심층 분석: 머신러닝 Q&A
많은 사람이 머신러닝을 먼 미래의 일이라고 생각합니다. 하지만 최근 머신러닝은 우리 생활에 점점 더 많이 등장하고 있습니다. 바둑이라는 놀라운 게임에 도전하는 Google의 컴퓨터나 Inbox by Gmail의 자동 답장 기능이 이러한 예가 될 수 있습니다. 이 모든 게 흥미롭긴 하지만 여전히 사람들은 머신러닝이 정확히 무엇인지, 왜 중요한지, 그리고 사진에서 강아지를 식별하는 것이 왜 말처럼 쉽지 않은지 궁금해합니다. 궁금증을 풀어드리고자 Google의 머신러닝 연구원인 Maya Gupta와 함께 머신러닝을 자세히 파헤쳐 보고자 합니다.
기초부터 시작해 보죠. 머신러닝이란 정확히 무엇인가요?
머신러닝이란 다수의 사례를 학습하고 사례에서 공통적인 규칙을 찾아낸 다음, 규칙을 사용해 새로운 사례를 예상하는 것입니다.
영화 추천을 예로 살펴보죠. 10억 명의 사람이 각자 좋아하는 영화 10편을 알려주었다고 가정해보겠습니다. 컴퓨터는 수많은 사례 중에서 사람들이 공통으로 좋아하는 영화가 무엇인지 찾아냅니다. 그런 다음 '공포 영화를 좋아하는 사람은 보통 로맨스를 좋아하지 않지만, 같은 배우가 나오는 영화는 장르와 관계없이 좋아한다'와 같이 사례를 설명하는 규칙을 밝혀냅니다. 이제 사용자가 잭 니콜슨이 출연한 '샤이닝'을 좋아한다고 알려 주면 컴퓨터는 사용자가 잭 니콜슨이 나오는 로맨틱 코미디 '사랑할 때 버려야 할 아까운 것들'을 좋아할지 추측해 낼 수 있고, YouTube에서 사용자가 좋아할 만한 다른 동영상을 추천할 수도 있습니다.
그렇군요. 조금이나마 이해가 되네요. 실제로는 어떤 식으로 작동되나요?
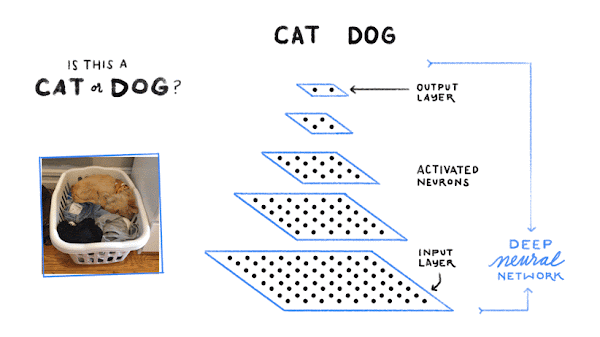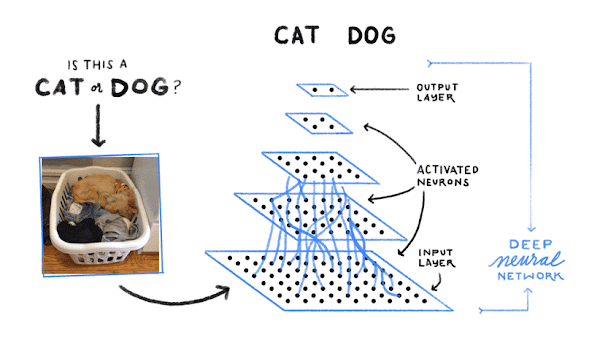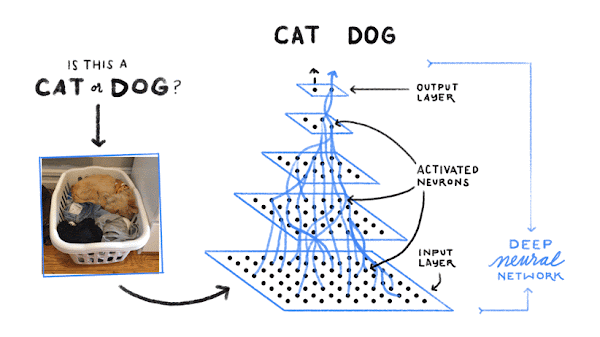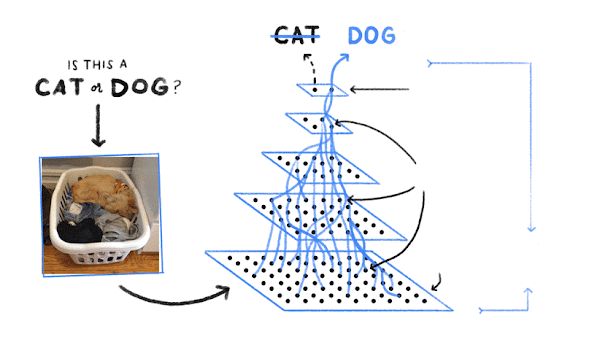
실제로 기계가 학습하는 규칙은 매우 복잡하고 말로 설명하기 어려울 수 있습니다. Google 포토를 생각해 보세요. 사진을 검색해 강아지가 등장하는 사진을 찾아주죠. Google은 어떻게 이렇게 할 수 있는 것일까요? 먼저 인터넷을 통해 '개'라는 라벨이 지정된 수많은 사진을 수집합니다. 마찬가지로 '고양이' 라벨이 지정된 수많은 사진, 그리고 여기에서 전부 언급할 수는 없지만 그 외 수백만 가지 대상의 사진을 수집합니다.

컴퓨터는 사진 속 대상이 고양이인지 개인지 또는 다른 무엇인지 추측하기 위한 픽셀 규칙과 색상 규칙을 찾습니다. 먼저 개를 식별할 수 있는 규칙을 임의로 추측합니다. 그런 다음 실제 개 이미지를 살펴보고 현재 규칙이 적합한지 확인합니다. 이때 고양이를 개로 잘못 식별했다면 사용하는 규칙을 약간 수정합니다. 다시 고양이 이미지를 보고 규칙을 수정하여 바로 잡기 위해 노력합니다. 이 과정을 수없이 반복합니다. 예를 살펴보고 사용하는 규칙이 올바르지 않다면 수정하여 더 나은 규칙을 찾아가는 것이죠.
결국 심층신경망과 같은 머신러닝 모델로부터 찾아낸 규칙으로 개나 고양이, 소방관 등 아주 많은 사물을 거의 정확하게 식별할 수 있는 것입니다.
정말 먼 미래의 이야기 같네요. 현재 머신러닝을 사용하는 다른 Google 제품에는 무엇이 있나요?
Google은 머신러닝을 매우 다양하게 적용하고 있습니다. 예를 들어 Google 번역의 경우 특정 언어로 작성된 거리 표지판이나 메뉴의 사진을 찍으면 사진 속 단어와 언어를 파악하여 놀랍게도 사용자의 언어로 즉석에서 번역해줍니다.
또한 뭐든 번역할 문장을 말하면 기계 학습이 적용된 음성 인식 기능이 작동합니다. 음성 인식은 여러 다른 제품에도 사용됩니다. Google 앱에서 음성 검색어를 처리하고, YouTube 동영상을 더욱 검색하기 쉽게 만드는 데도 음성 인식이 활용되죠.



표지판이든 메뉴든 카메라에 담기만 하면 바로 번역해 줍니다. 인터넷 연결도 필요 없죠. *워드렌즈는 영어와 24개 이상의 언어 간에 사용할 수 있습니다.
다른 언어를 사용하는 사람과 대화할 수 있습니다.
키보드에서 지원되지 않는 문자와 단어를 간편하게 손으로 써서 검색할 수 있습니다.
번역할 단어를 입력하기만 하면 됩니다.
최근 Google에서 머신러닝에 큰 관심을 보이는 이유는 무엇인가요?
머신러닝은 새로운 것이 아니며 18세기 통계학을 기반으로 합니다. 그러나 말씀하신 것처럼 최근에 큰 관심을 갖게 된 데에는 3가지 이유가 있습니다.
첫째로 컴퓨터가 정확한 예측을 할 수 있도록 가르치려면 수많은 사례가 필요합니다. 사진에서 강아지를 찾는 것처럼 사람이 아주 쉽게 할 수 있는 일이라도 말이죠. 이제 인터넷 사용자들의 활동 덕분에 컴퓨터가 학습할 수 있는 풍부한 사례를 수집할 수 있게 되었습니다. 예를 들어 전 세계의 웹사이트에는 각 언어로 '개'라고 라벨이 지정된 개 사진이 무수히 많습니다.
하지만 사례만 많이 수집한다고 되는 것이 아닙니다. 웹캠으로 여러 장의 개 사진을 보여주는 것만으로 모든 것을 배우기를 바라면 안 되는 거죠. 컴퓨터에 학습 프로그램이 필요합니다. 그리고 최근 Google을 비롯한 현장의 연구진은 머신러닝 프로그램의 복잡성과 성능 측면에서 의미 있는 성과를 거뒀습니다.
그러나 여전히 프로그램은 완벽하지 않고 컴퓨터도 생각만큼 똑똑하지 않기 때문에 수많은 사례를 수없이 확인하고 디지털 신호를 조정하여 정확한 프로그램을 완성해야 합니다. 이 모든 과정에는 엄청난 수준의 연산 성능과 복잡한 프로세스가 필요합니다. 하지만 소프트웨어와 하드웨어의 발전 덕분에 가능하게 되었죠.
컴퓨터가 지금은 할 수 없지만 머신러닝으로 인해 곧 할 수 있게 될만한 작업이 있다면요?
실제로 얼마 전까지 음성 인식 기능은 전화 마이크에 대고 말한 신용카드 번호 10자리도 잘 인식하지 못했습니다. 그러나 정교한 머신러닝을 통해 지난 5년 동안 상당히 발전했고 지금은 Google 검색을 실행하는 데도 음성 인식을 사용할 수 있습니다. 그리고 계속해서 더 빠르게 발전하고 있죠.
또한 머신러닝은 옷을 고르는 데에도 도움을 주게 될 것입니다. 다른 분들은 어떨지 모르지만 저는 옷을 입어보는 것을 정말 싫어해요. 그래서 그냥 적당한 청바지 브랜드를 찾은 다음 거기에서 5벌을 구매하죠. 하지만 머신러닝은 나에게 어울리는 브랜드 데이터를 통해 나에게 어울리는 다른 옷을 추천해줄 수도 있을 것입니다. 패션은 Google의 사업 분야는 아니지만, 누군가 이런 기능을 개발하고 있었으면 좋겠네요.
10년 후에는 머신러닝이 어떻게 달라져 있을까요?
모든 전문가가 공통으로 연구하는 내용이 있는데, 바로 더 적은 사례로 더 빠르게 학습하는 방법입니다. Google에서는 기계에 더 많은 상식을 제공하는 방식으로 접근합니다. 이 분야에서는 이를 '규칙화'라고 부르죠.
기계에 상식을 제공한다는 것이 무슨 말이냐고요? 일반적으로 사례의 작은 변화에 기계가 크게 흔들려서는 안 된다는 말입니다. 강아지가 카우보이 모자를 쓴 사진 역시 강아지라는 결과를 내놓아야 하는 거죠.
머신러닝이 카우보이 모자와 같이 작고 중요하지 않은 변화의 영향을 덜 받게 함으로써 학습 프로그램의 상식을 강화합니다. 말은 쉽지만 잘못하면 기계가 중요한 변화에 민감하게 반응하지 못할 수 있습니다. 따라서 균형을 맞추기 위해 계속해서 노력하고 있습니다.

머신러닝의 어떤 부분에 가장 큰 흥미를 느끼시나요? 어떤 점이 동기부여가 되는지 궁금합니다.
저는 시애틀에서 자랐고 Meriwether Lewis나 William Clark 같은 서부의 초기 탐험가에 관해 많이 듣고 자랐습니다. 머신러닝 연구에도 이와 같은 탐험 정신이 있습니다. 처음 접하는 분야이고 근사한 미래를 설계하는 일이죠.
Google의 머신러닝을 표현할 만한 슬로건이 있다면 뭐가 좋을까요?
처음에 성공하지 못하더라도 수만 번이든 될 때까지 해보세요.



