Questions et réponses sur le machine learning
Pour nombre d'entre nous, le machine learning (apprentissage automatique) semble assez futuriste. Pourtant, depuis quelque temps, on le retrouve de plus en plus dans notre quotidien, que ce soit sous la forme d'un ordinateur Google livrant une partie de go palpitante ou de la création de réponses automatiques dans Inbox by Gmail. Aussi passionnant que ce soit, certains d'entre nous se demandent encore ce qu'est exactement le machine learning, pourquoi cette technologie est importante ou encore pourquoi identifier un chien sur une photo n'est pas aussi simple qu'il n'y paraît. Nous avons donc demandé à Maya Gupta, chercheuse chez Google dans le domaine du machine learning, de nous expliquer tout cela.
Commençons par le commencement. Qu'est-ce que le machine learning exactement ?
Le machine learning consiste à rassembler une grande quantité d'exemples pour déterminer les schémas sous-jacents, puis à les utiliser pour effectuer des prévisions concernant de nouveaux exemples.
Prenons l'exemple des recommandations de films. Supposons qu'un milliard d'individus nous donnent le titre de leur film préféré. Ces informations peuvent alors être utilisées par un ordinateur pour déterminer les points communs entre tous ces films. L'ordinateur va ainsi formuler des propositions explicitant les schémas qu'il a déterminés, par exemple : "les gens qui aiment les films d'horreur n'aiment généralement pas les films romantiques, mais ils aiment les films dans lesquels les mêmes acteurs jouent". Ensuite, si vous dites à l'ordinateur que vous avez aimé "Shining" avec Jack Nicholson, il peut deviner avec un certain niveau de confiance que vous aimerez la comédie romantique "Tout peut arriver", avec Jack Nicholson également, et vous recommander d'autres vidéos sur YouTube.
J'ai compris. Enfin je crois. Mais concrètement, comment ça marche ?
Concrètement, les schémas que la machine apprend peuvent être très complexes et très difficiles à expliquer. Prenons l'exemple de Google Photos, qui vous permet de rechercher dans vos photos celles qui comportent un chien. Comment Google procède-t-il ? Eh bien, nous rassemblons tout un tas de photos étiquetées "chien" (merci Internet !). Nous rassemblons également de nombreuses photos étiquetées "chat", ainsi que des photos avec un million d'autres étiquettes, dont je vous épargne la liste :).

Ensuite, l'ordinateur recherche des schémas de pixels et de couleurs qui aident à déterminer s'il s'agit d'un chat, d'un chien ou d'autre chose. Au début, il tente de deviner, aléatoirement, les schémas pertinents pour identifier un chien. Ensuite, il prend une photo de chien et regarde si ces schémas permettent de l'identifier correctement comme tel. S'il se trompe et prend un chat pour un chien, il va modifier légèrement les schémas sur lesquels il se base. Enfin, il prend une photo de chat et ajuste à nouveau ses schémas pour essayer d'identifier correctement l'animal. L'ordinateur répète ce processus un milliard de fois : il recherche un exemple et, s'il se trompe, modifie les schémas qu'il utilise pour faire mieux la fois suivante.
Au final, les schémas constituent un modèle d'apprentissage automatique, comme un réseau de neurones profond, capable d'identifier (la plupart du temps) correctement les chiens, les chats, les pompiers, et bien plus.
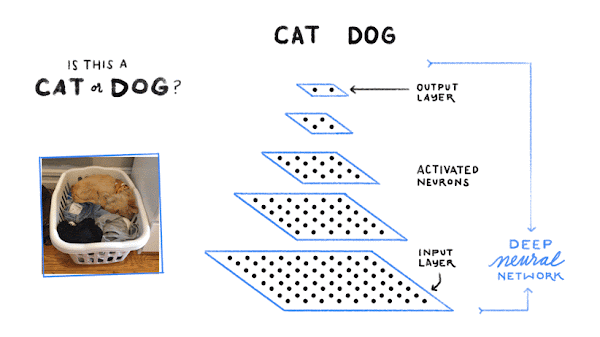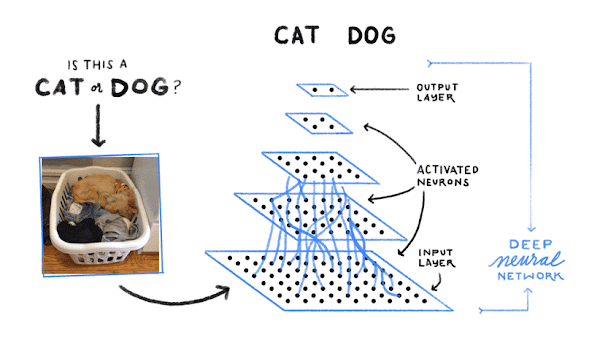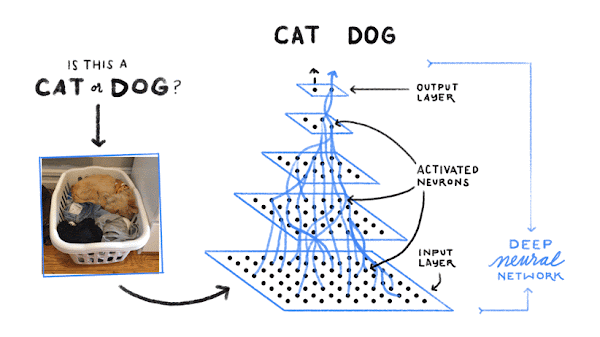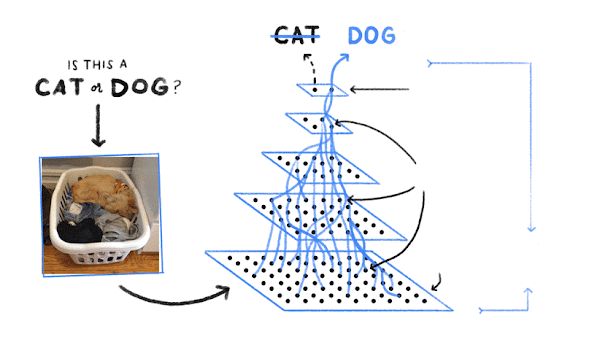
Tout cela semble très futuriste. Quels autres produits Google font aujourd'hui appel au machine learning ?
Google utilise le machine learning dans de très nombreux produits. Par exemple, vous pouvez prendre en photo un panneau ou un menu dans une langue, et Google Traduction est capable de déterminer les mots et la langue de la photo, puis de les traduire dans votre langue, en temps réel, comme par magie.
Vous pouvez aussi prononcer n'importe quel mot dans Google Traduction, et la reconnaissance vocale, qui repose sur le machine learning, fait le reste. La reconnaissance vocale est également utilisée dans quantité d'autres produits, comme les commandes vocales pour l'appli Google ou pour l'amélioration de la recherche de vidéos sur YouTube.



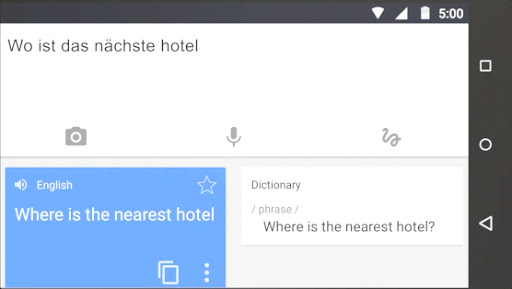
Dirigez l'appareil photo vers un panneau, un menu ou autre pour en obtenir aussitôt la traduction. Vous n'avez même pas besoin d'être connecté à Internet. * Word Lens est disponible en anglais et dans plus d'une vingtaine de langues.
Discutez avec une personne qui ne parle pas votre langue.
Tracez à la main les caractères et les mots dans une langue que votre clavier ne vous permet pas de saisir.
Saisissez simplement les mots à traduire.
Pourquoi est-ce que Google parle beaucoup du machine learning en ce moment ?
Le machine learning n'est pas vraiment une nouveauté, c'est une technologie qui trouve son origine dans le domaine des statistiques au XVIIIe siècle. Mais vous avez parfaitement raison, c'est un sujet dont on parle beaucoup ces derniers temps, et ce pour trois raisons.
La première, c'est que les ordinateurs ont besoin d'un grand nombre d'exemples pour apprendre à réaliser des prévisions correctes, même pour des choses que vous ou moi trouverions faciles (comme reconnaître un chien sur une photo). Internet est le lieu d'une activité phénoménale, et de ce fait constitue une mine formidable d'exemples à partir desquels les ordinateurs peuvent apprendre. On trouve, par exemple, des millions de photos de chien étiquetées "chien" sur des sites Web créés aux quatre coins du globe, dans toutes les langues.
Mais il ne suffit pas de disposer d'une grande quantité d'exemples. On ne peut pas montrer toutes ces photos à une webcam et s'attendre à ce qu'elle apprenne quoi que ce soit ; l'ordinateur a besoin d'un programme d'apprentissage. Dernièrement, le domaine (et Google) a connu des avancées majeures en matière de complexité et de puissance des programmes de machine learning.
Cependant, nos programmes ne sont pas encore parfaits et, les ordinateurs, pas encore très intelligents. Avant que cela ne fonctionne, nous devons utiliser une grande quantité d'exemples de très nombreuses fois afin d'apporter toute une série de modifications. Tout cela nécessite une puissance de calcul considérable et un traitement en parallèle sophistiqué. Mais de nouvelles avancées matérielles et logicielles ont rendu tout cela possible.
Qu'est-ce que les ordinateurs ne peuvent actuellement pas faire, mais qu'ils seront bientôt capables de réaliser grâce au machine learning ?
Hier encore, la reconnaissance vocale peinait à reconnaître les 10 chiffres de votre carte de paiement lorsque vous les prononciez au téléphone. La reconnaissance vocale a connu de formidables avancées ces cinq dernières années grâce à des technologies avancées de machine learning, si bien que vous pouvez à présent l'utiliser pour effectuer des recherches Google. Et cette technologie s'améliore rapidement.
Je pense que le machine learning va même nous permettre de mieux nous habiller. Je ne sais pas pour vous, mais moi j'ai horreur d'essayer des vêtements. Lorsque je trouve une marque de jeans qui me va, j'en achète cinq. Mais le machine learning peut utiliser les exemples de marques qui nous vont bien pour nous recommander d'autres marques qui nous iraient tout aussi bien. Ce problème ne fait pas partie du domaine d'investigation de Google, mais j'espère bien que quelqu'un travaille à le résoudre !
À quoi ressemblera le machine learning dans 10 ans ?
L'un des domaines de recherche actuels du secteur est l'accélération du processus d'apprentissage à partir d'un nombre d'exemples plus faible. L'une des approches pour y parvenir, sur laquelle Google travaille d'ailleurs d'arrache-pied, consiste à améliorer le bon sens des machines, que nous appelons dans notre jargon la "régularisation".
Qu'est-ce que le bon sens pour une machine ? En général, on entend par là que si un exemple varie légèrement, la machine ne doit pas changer d'avis. Par exemple, la photo d'un chien avec un chapeau de cowboy est toujours une photo de chien.
Nous mettons en œuvre ce type de bon sens dans le programme d'apprentissage en rendant le machine learning insensible aux petites modifications insignifiantes, telles qu'un chapeau de cowboy. C'est facile à dire, mais si vous vous trompez, vous pouvez rendre la machine insensible aux modifications significatives ! C'est un équilibre que nous essayons encore de trouver.

Qu'est-ce qui vous passionne le plus dans le machine learning ? Qu'est-ce qui vous motive à travailler dans ce domaine ?
J'ai grandi à Seattle, où l'on nous parle beaucoup des premiers explorateurs de l'Ouest américain tels que Lewis et Clark. La recherche dans le domaine du machine learning procède du même esprit d'aventure. Nous découvrons des choses pour la première fois et nous tentons de tracer la voie vers un avenir meilleur.
Si vous deviez trouver un slogan pour le machine learning chez Google, quel serait-il ?
Si vous ne réussissez pas du premier coup, réessayez un milliard de fois.



